Introduction
This is the third in a series of six articles, following the design, development and practical use of a fully functional ASP.NET custom control.
The full list of articles is as follows:
These articles are not intended to be a comprehensive look at custom control development (there are 700+ page books that barely cover it), but they do cover a significant number of fundamentals, some of which are poorly documented elsewhere.
The intent is to do so in the context of a single fully reusable and customizable control (as opposed to many contrived examples) with some awareness that few people will want many parts of the overall article but many people will want few parts of it.
This article examines the JavaScript rendering methods provided by the Page class and how to render JavaScript to be applied to all instances of a control when the page loads, without repeating the code. It is intended for people who know how to render a control but are new to rendering script blocks.
It assumes a basic knowledge of C#, .NET string manipulation, JavaScript v1.0 and WebControl-derived classes.
Downloads are available from the first article of the series.
Encoding / Decoding Functionality
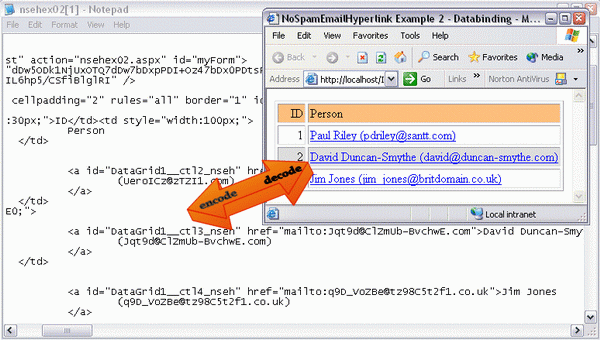
The encoding functionality is executed at the server and is written in C#, the decoding happens at the client and thus is written in JavaScript.
The algorithm used to encode the email address is defined in detail by the first article of this series: NoSpamEmailHyperlink: 1. Specification
One subtle change reverses the entire process.
Encoding: C#
protected virtual string Encode (string Unencoded)
{
char[] scramble = Email.ToCharArray();
int baseNum = ScrambleSeed;
bool subtract = true;
int atSymbol = Array.IndexOf(scramble, '@');
if (atSymbol == -1) atSymbol = 0;
int stopAt = Array.IndexOf(scramble, '.', atSymbol);
if (stopAt == -1) stopAt = scramble.Length;
for (int i=0; i < stopAt; i++)
{
char ch = scramble[i];
int idx = CodeKey.IndexOf(ch);
if (idx < 0) continue;
idx += (subtract ? -baseNum : baseNum);
baseNum -= (subtract ? -i : i);
while (idx < 0) idx += CodeKey.Length;
idx %= CodeKey.Length;
scramble[i] = CodeKey[idx];
subtract = !subtract;
}
return new string(scramble);
}
The code is not too complicated, we simply find the start and end points for encoding and adjust each alphanumeric character with another alphanumeric character, using the algorithm we have already defined.
The start point at the server is always the first character, the end point is the index of the first period after the @ symbol. If there is no @ symbol or no period after it then we are not dealing with a valid email address, however we set the end point to the end of the string (i.e. encode the whole string) to make the algorithm more complete.
This is, of course, an arbitrary decision. You could as easily choose not to encode the string at all or even throw an exception. Invalid email addresses should not be a major concern here.
Decoding: JavaScript
function NoSpamEmailHyperlink_DecodeScript(link, seed)
{
var ky = "yJzdeB4CcDnmEFbZtvuHlI1hA8SiLo9MwfN3O6Y5QaRqKTjUpxVk2WgXrP7Gs0";
var storeText = link.innerHTML;
var baseNum = parseInt(seed);
var atSym = link.href.indexOf("@");
if (atSym == -1) atSym = 0;
var dotidx = link.href.indexOf(".", atSym);
if (dotidx == -1) dotidx = link.href.length;
var scramble = link.href.substring(7, dotidx);
var unscramble = "";
var su = true;
for (i=0; i < scramble.length; i++)
{
var ch = scramble.substring(i,i + 1);
var idx = ky.indexOf(ch);
if (idx < 0)
{
unscramble = unscramble + ch;
continue;
}
idx -= (su ? -baseNum : baseNum);
baseNum -= (su ? -i : i);
while (idx < 0) idx += ky.length;
idx %= ky.length;
unscramble = unscramble + ky.substring(idx,idx + 1);
su = !su;
}
var emAdd = unscramble + link.href.substring(dotidx, link.href.length + 1);
link.href = "mailto:" + emAdd;
var findEm = storeText.indexOf(scramble);
while (findEm > -1)
{
storeText = storeText.substring(0, findEm) + emAdd +
storeText.substring(findEm + emAdd.length, storeText.length);
findEm = storeText.indexOf(scramble);
}
link.innerHTML = storeText;
}
Apart from the obvious changes that come with translating from C# to JavaScript and some variable names reduced for a number of reasons, there are essentially two major changes from the Encode functionality.
First, to reverse the entire coding process, the line
idx += (subtract ? -baseNum : baseNum);
has been reversed to make
idx -= (su ? -baseNum : baseNum);
Secondly, rather than receiving the email address (and optionally some text) and returning the converted string, this function receives a link object and the seed, parses the email address from the href property, decodes it and replaces any occurrence of the original (encoded) email address in the link's innerHTML property.
Note that in early versions of Netscape (4.x or earlier), we cannot decode the email address in the innerHTML property, so we remove the code which stores and amends that property.
This makes it possible to decode all of the NoSpamEmailHyperlinks on the page using one of the following simple startup script blocks:
Internet Explorer / Opera
for (i = 0; i < LinkNames.length; i++)
{
NoSpamEmailHyperlink_DecodeScript(
document.links.item(LinkNames[i]), Seed[i]
);
}
Other Browsers
for (i = 0; i < document.links.length; i++)
{
for (j = 0; j < LinkNames.length; j++)
{
if (LinkNames[j] == document.links[i].id)
{
NoSpamEmailHyperlink_DecodeScript(
document.links[i], Seed[j]
);
}
}
}
In fact, we use longer field names than this, to avoid any conflict with JavaScript from other controls, but that is not important for now.
Building the JavaScript
To build both the function script and the calling script, the NoSpamEmailHyperlink uses the JavaScriptBuilder class as described in another article by the same author:
JavaScriptBuilder: JavaScript Handler Class for Custom Controls.
There are two significant advantages of this approach for the NoSpamEmailHyperlink project:
- The ability to efficiently insert field names into the script using overridable properties.
- The ability to compress the code for a release version of the control, making it nearly unreadable to the uninitiated viewer (the email harvester).
The former is covered in much more detail in the final part of this series: NoSpamEmailHyperlink: 6. Customization.
The latter is discussed in great detail in the JavaScriptBuilder article, but a short demonstration is useful here.
The JavaScript listed above is built using the following code:
protected virtual string GetFuncScript()
{
#if DEBUG
JavaScriptBuilder jsb = new JavaScriptBuilder(true);
#else
JavaScriptBuilder jsb = new JavaScriptBuilder();
#endif
jsb.AddLine("function ", FuncScriptName, "(link, seed)");
jsb.OpenBlock();
jsb.AddCommentLine("This is the decoding key for all ",
LinkArrayName, " objects");
jsb.AddLine("var ", CodeKeyName, " = \"", CodeKey, "\";");
jsb.AddLine();
if (!BrowserNeedsHide)
{
jsb.AddCommentLine("Store the innerHTML so that it doesn't get");
jsb.AddCommentLine("distorted when updating the href later");
jsb.AddLine("var storeText = link.innerHTML;");
jsb.AddLine();
}
jsb.AddCommentLine("Initialize variables");
jsb.AddLine("var baseNum = parseInt(seed);");
jsb.AddLine("var atSym = link.href.indexOf(\"@\");");
jsb.AddLine("if (atSym == -1) atSym = 0;");
jsb.AddLine("var dotidx = link.href.indexOf(\".\", atSym);");
jsb.AddLine("if (dotidx == -1) dotidx = link.href.length;");
jsb.AddLine("var scramble = link.href.substring(7, dotidx);");
jsb.AddLine("var unscramble = \"\";");
jsb.AddLine("var su = true;");
jsb.AddLine();
jsb.AddCommentLine("Go through the scrambled section of the address");
jsb.AddLine("for (i=0; i < scramble.length; i++)");
jsb.OpenBlock();
jsb.AddCommentLine("Find each character in the scramble key string");
jsb.AddLine("var ch = scramble.substring(i,i + 1);");
jsb.AddLine("var idx = ", CodeKeyName, ".indexOf(ch);");
jsb.AddLine();
jsb.AddCommentLine("If it isn't there then add the character");
jsb.AddCommentLine("directly to the unscrambled email address");
jsb.AddLine("if (idx < 0)");
jsb.OpenBlock();
jsb.AddLine("unscramble = unscramble + ch;");
jsb.AddLine("continue;");
jsb.CloseBlock();
jsb.AddLine();
jsb.AddCommentLine("Decode the character");
jsb.AddLine("idx -= (su ? -baseNum : baseNum);");
jsb.AddLine("baseNum -= (su ? -i : i);");
jsb.AddLine("while (idx < 0) idx += ", CodeKeyName, ".length;");
jsb.AddLine("idx %= ", CodeKeyName, ".length;");
jsb.AddLine();
jsb.AddCommentLine("... and add it to the unscrambled email address");
jsb.AddLine("unscramble = unscramble + ", CodeKeyName,
".substring(idx,idx + 1);");
jsb.AddLine("su = !su;");
jsb.CloseBlock();
jsb.AddLine();
jsb.AddCommentLine("Adjust the href property of the link");
jsb.AddLine("var emAdd = unscramble + link.href.substring(",
"dotidx, link.href.length + 1);");
jsb.AddLine("link.href = \"mailto:\" + emAdd;");
jsb.AddLine();
if (!BrowserNeedsHide)
{
jsb.AddCommentLine("If the scrambled email address is also in the text");
jsb.AddCommentLine("of the hyperlink, replace it");
jsb.AddLine("var findEm = storeText.indexOf(scramble);");
jsb.AddLine("while (findEm > -1)");
jsb.OpenBlock();
jsb.AddLine("storeText = storeText.substring(0, findEm) + emAdd ",
"+ storeText.substring(findEm + emAdd.length, storeText.length);");
jsb.AddLine("findEm = storeText.indexOf(scramble);");
jsb.CloseBlock();
jsb.AddLine();
jsb.AddLine("link.innerHTML = storeText;");
}
jsb.CloseBlock();
return jsb.ToString();
}
The BrowserNeedsHide property simply checks the Page.Request.Browser for Netscape versions 4.x or below, where decoding the email address in the link's innerHTML property is not possible.
[
DesignerSerializationVisibility(DesignerSerializationVisibility.Hidden)
]
protected virtual bool BrowserNeedsHide
{
get
{
HttpBrowserCapabilities bc = Page.Request.Browser;
Version bv = new Version(bc.Version);
return (bc.Browser.ToLower().IndexOf("netscape") > -1
&& bv.Major < 5);
}
}
We have already looked at the JavaScript generated in the debug version of the DLL but when you generate a release version, the script is compressed to one line with no comments. Assuming BrowserNeedsDecode is false, that will look much like the following:
function NoSpamEmailHyperlink_DecodeScript(link, seed) { var ky =
"yJzdeB4CcDnmEFbZtvuHlI1hA8SiLo9MwfN3O6Y5QaRqKTjUpxVk2WgXrP7Gs0"; var storeText =
link.innerHTML; var baseNum = parseInt(seed); var atSym = link.href.indexOf("@");
if (atSym == -1) atSym = 0; var dotidx = link.href.indexOf(".", atSym); if
(dotidx == -1) dotidx = link.href.length; var scramble = link.href.substring(7,
dotidx); var unscramble = ""; var su = true; for (i=0; i < scramble.length; i++)
{ var ch = scramble.substring(i,i + 1); var idx = ky.indexOf(ch); if (idx < 0)
{ unscramble = unscramble + ch; continue; } idx -= (su ? -baseNum : baseNum);
baseNum -= (su ? -i : i); while (idx < 0) idx += ky.length; idx %= ky.length;
unscramble = unscramble + ky.substring(idx,idx + 1); su = !su; } var emAdd =
unscramble + link.href.substring(dotidx, link.href.length + 1); link.href =
"mailto:" + emAdd; var findEm = storeText.indexOf(scramble); while (findEm >
-1) { storeText = storeText.substring(0, findEm) + emAdd +
storeText.substring(findEm + emAdd.length, storeText.length); findEm =
storeText.indexOf(scramble); } link.innerHTML = storeText; }
It takes full-featured JavaScript handling software to be able to interpret code of this nature. Any future email harvester that is set up to do so will almost certainly be very expensive. However, current versions of Internet Explorer, Netscape and Opera will have no problems handling this code.
Note also that this code, once compressed, is less than 1kb in length and thus not a heavy drain on bandwidth.
Rendering the JavaScript
The necessary JavaScript is registered with the page in the OnPreRender event. The primary advantage of this is to avoid script blocks being built when rendering in the designer, which does not support JavaScript. But be aware: RegisterClientScriptBlock() will not work if registered later in the lifespan of the control. Client script blocks are rendered before the control itself, so if you register them in an override of Render() then they are not registered when the page is rendering client scripts.
protected override void OnPreRender(EventArgs e)
{
base.OnPreRender (e);
if (Email.Length > 0)
{
Page.RegisterArrayDeclaration(
LinkArrayName, String.Format("\"{0}\"", ClientID)
);
Page.RegisterArrayDeclaration(
SeedArrayName, String.Format("\"{0}\"", ScrambleSeed)
);
if (!Page.IsClientScriptBlockRegistered(FuncScriptName))
Page.RegisterClientScriptBlock(FuncScriptName, GetFuncScript());
if (!Page.IsStartupScriptRegistered(CallScriptName))
Page.RegisterStartupScript(CallScriptName, GetCallScript());
}
}
The decoding function is registered as a client script block, so that it is downloaded before the HTML for the controls themselves. If we do not do this, a slow download across a 56Kbps modem will display the links in the browser before the decoding script is downloaded and run. This can show the encoded address noticeably before it changes.
However, the script block that calls the decoding function is registered as a startup script block, so that it is downloaded after the controls and array have been rendered. We do this because the script does not contain a function and thus will be run immediately. As it needs to access the control HTML and the arrays, we need them to download first.
Each script block should only be registered once, no matter how many instances of the control appear on a page. In fact, the framework will only allow you to register the script once. If you call Page.RegisterStartupScript twice with the same key, it will ignore the second call. However, it is clearer and more efficient to make that check yourself as seen above.
The array registration methods, on the other hand, will be called from multiple instances of this control, creating an array of the hyperlink IDs and a matching array of the decoding seeds.
Notice that the registration names of the arrays and script blocks are taken from properties. There are two reasons for this:
- The property can include the name of the control type, so that inherited controls will not clash.
- The array names can be made more difficult to identify by changing the name in inherited controls.
This subject is covered in much more detail in a later article: NoSpamEmailHyperlink: 6. Customization.
Note that when you register a string value to an array, you need to include the quotes. If your page includes five NoSpamEmailHyperlink controls, named "ns1"..."ns5" and with seeds incrementing from the default of "23", the array registration will then generate the following code block:
var NoSpamEmailHyperlink_LinkNames =
new Array("ns1", "ns2", "ns3", "ns4", "ns5");
var NoSpamEmailHyperlink_Seeded = new Array("23", "24", "25", "26", "27");
.NET "Feature" Alert
You may be asking yourself why, given that we can remove the quotes, we are not registering the seeds as integers. This is fine when we have an array of five items, as above. But if you want to register only one instance of the control on a page the generated code would look like this:
var NoSpamEmailHyperlink_LinkNames = new Array("ns1");
var NoSpamEmailHyperlink_Seeded = new Array(23);
The second line of this code does not create an array containing one item with a value of 23. Instead it creates an array of 23 "undefined" items. This can be a difficult bug to track down, as I learned the hard way, so get into the habit of using quotes for all array registrations.
Conclusion
Combining the code from the second and third articles, we now have a fully functional custom control for encoding and decoding a given email address both in the href="mailto:..." attribute and in the body of the hyperlink.
Now that the .Encode() method actually does some work, a NoSpamEmailHyperlink control with these settings:
<cpspam:NoSpamEmailHyperlink id="nseh" runat="server"
Email="pdriley@santt.com" ScrambleSeed="181">
Paul Riley (pdriley@santt.com)
</cpspam:NoSpamEmailHyperlink>
will render the following HTML.
Netscape 4.x or below
<a id="nseh" href="mailto:WsyhiJc@7kDit.com">
Paul Riley ([Hidden])
</a>
Other Browsers
<a id="nseh" href="mailto:WsyhiJc@7kDit.com">
Paul Riley (WsyhiJc@7kDit.com)
</a>
Being a perfectly valid email address, the encoded address should set off no alarms with email validators and will only be recognized as invalid by email harvesters with verification software (already significantly more expensive than those without).
Reducing the usefulness of data we leave available to the email harvesters can only reduce their profitability as well as protect our registered users.
In this article, we have examined the JavaScript registration functions and how they can be used to manipulate any number of instances of your control on a single page without repetitive code.
We have also looked at one example of a simple but very powerful encryption algorithm and how to implement this in C# while easily reversing the process in JavaScript.
Next we will look at making our new control look more professional in a WYSIWYG designer such as Visual Studio .NET.
Revision History
- 1.0 12-Oct-2003 - Created.
- 1.1 23-Oct-2003 - Changed
innerText to innerHTML. Conditionalized decode script for early Netscape.

